

Yarn Label 可以基于节点标签的信息,对任务的分布进行细粒度控制。该特性从 Hadoop 2.6 版本开始引入,到了 Hadoop 2.8 开始才较为成熟,可以根据节点的一些角色定位、处理能力(结合具体业务场景)等按需对节点划分为几个不同的区域(分组),并可以让作业在指定分区下的节点上运行。
当前 Yarn Label 只能基于 Capacity 调度方式进行工作,暂不支持其他调度方式。
Yarn Label 需要结合节点、用户队列使用,三者结构如下:

一个 Label 下可以有多个 Node,一个 Lable 可以被多个 Queue 共享,一个 Queue 可以有多个 Lable。
1. 开启 Yarn Lables 相关功能
环境信息如下:
- Ambari 2.7.3
- HDP 3.1.0
- 鲲鹏服务器(arm):agent1
- 戴尔服务器(x86):agent2
首先开启 Yarn 服务下的 Node Labels 功能(等同于修改 yarn-site.xml 的 yarn.node-labels.enabled 为 true):

在 HDFS 上创建一个存储 Node Lables 信息的路径:
sudo su hdfs
hadoop fs -mkdir -p /yarn/node-labels
hadoop fs -chown -R yarn:yarn /yarn
hadoop fs -chmod -R 700 /yarn创建 yarn 用户目录:
hadoop fs -mkdir -p /user/yarn
hadoop fs -chown -R yarn:yarn /user/yarn
hadoop fs -chmod -R 700 /user/yarn修改 Yarn 服务的 YARN Node Labels FS Store Root directory 存储路径为前面 HDFS 创建好的路径(相当于修改 yarn-site 的 yarn.node-labels.fs-store.root-dir 属性):
重启 Yarn 服务。
2. 添加 Node Labels
Node Lables 会根据我们指定的 label,将集群的节点划分为一个个 partition,一个节点只可以有一个 lable。如果不分配 lable,则节点默认属于 Default partition(即 partition="")。
这里我们添加 kunpeng 以及 dell 两种 label:
sudo -u yarn yarn rmadmin -addToClusterNodeLabels "kunpeng(exclusive=true),dell(exclusive=true)"exclusive 表示 partition 是否独占,默认为 true。两种配置的含义分别如下:
- true: containers 只会分配到完全匹配的节点上。例如,一个 partition 只能被 partition 指定为 x 的任务访问。如果任务不指定 label,则会分配到 Default partition 的节点上。

- false:如果一个 partition 是非独占的,那么当有空闲资源时,也可以共享给 Default partition 下的任务。
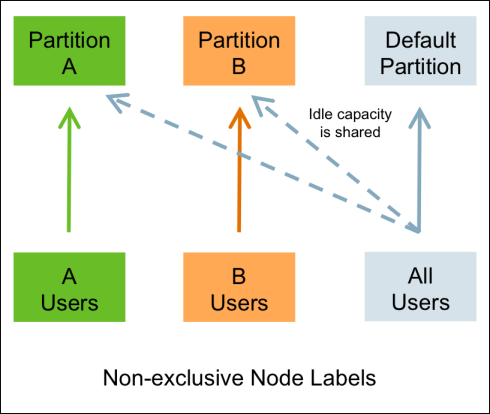
关于独占与非独占的区别,更具体的信息可以参考 HDP 的文档:Chapter 5. Node Labels。
绝大部分场景下,最好设置为独占,让分布式作业只跑在一种架构下,避免低配的机器与高配机器产生 “木桶原理” 的现象。
如果需要删除 label,则需要确保 label 没有分配到队列才能删除:
sudo -u yarn yarn rmadmin -removeFromClusterNodeLabels "<label>[,<label>,...]"如果需要查看创建的 label,执行下列命令:
sudo -u yarn yarn cluster --list-node-labels3. 节点分配 Label
节点分配 label 的语法如下:
sudo -u yarn yarn rmadmin -replaceLabelsOnNode "node1[:port]=label1 node2=label2" [-failOnUnknownNodes]如果不指定 [:prot] ,就会分配给该节点上的全部 NM,从这里也可以看出,Node Labels 的作用粒度其实是在 NM 上,而非节点上,一个节点可以有多个 NM。
如果指定了 -failOnUnknownNodes,那么当命令中有未知节点时,命令会失败。
如果想要查看节点分配的 label,需要先获取节点的 ID,例如(下列信息来自 HDP 文档):
[root@node-1 /]# sudo -u yarn yarn node -list
14/11/21 12:14:06 INFO impl.TimelineClientImpl: Timeline service address: http://node-1.example.com:8188/ws/v1/timeline/
14/11/21 12:14:07 INFO client.RMProxy: Connecting to ResourceManager at node-1.example.com/240.0.0.10:8050
Total Nodes:3
Node-Id Node-State Node-Http-Address Number-of-Running-Containers
node-3.example.com:45454 RUNNING node-3.example.com:50060 0
node-1.example.com:45454 RUNNING node-1.example.com:50060 0
node-2.example.com:45454 RUNNING node-2.example.com:50060 0然后根据节点 ID 获取节点的具体信息:
[root@node-1 /]# yarn node -status node-1.example.com:45454
14/11/21 06:32:35 INFO impl.TimelineClientImpl: Timeline service address: http://node-1.example.com:8188/ws/v1/timeline/
14/11/21 06:32:35 INFO client.RMProxy: Connecting to ResourceManager at node-1.example.com/240.0.0.10:8050
Node Report :
Node-Id : node-1.example.com:45454
Rack : /default-rack
Node-State : RUNNING
Node-Http-Address : node-1.example.com:50060
Last-Health-Update : Fri 21/Nov/14 06:32:09:473PST
Health-Report :
Containers : 0
Memory-Used : 0MB
Memory-Capacity : 1408MB
CPU-Used : 0 vcores
CPU-Capacity : 8 vcores
Node-Labels : x3. 队列绑定 Label
NM 分配 node 有 Centralized 、Distributed 、Delegated-Centralized 这几种方式,Ambari 默认为第一种方式。
Centralized:节点与 label 的映射可以通过 RM 暴露的 CLI, REST 或者 RPC 进行配置。
在 Ambari 的队列配置界面,配置 root 父队列占用 kunpeng、dell 的全部资源,同时设置任务不指定 label 时默认 label 为 kunpeng :

配置 haohan、default 队列各占 kunpeng、dell 一半资源:

子队列无需配置默认 label,默认会继承父队列的规则。Ambari 会按照 Yarn 的规则,自动生成相应的配置。
最后点击保存并刷新队列:

这里有一点需要注意,同个 label 在不同队列中也是需要指定百分比的,不同队列相同 label 最终的比例之和需要等于 100%,此时队列之间的资源比例,仅作用于未指定 label 的节点上。
配置完毕之后,可以通过以下几种方式指定 label:
API 方式:
ApplicationSubmissionContext.setNodeLabelExpression(..)to set node label expression for all containers of the application.ResourceRequest.setNodeLabelExpression(..)to set node label expression for individual resource requests. This can overwrite node label expression set in ApplicationSubmissionContext- Specify
setAMContainerResourceRequest.setNodeLabelExpressioninApplicationSubmissionContextto indicate expected node label for application master container.
Hadoop 运行 jar 包方式:
hadoop jar xxx.jar -Dmapreduce.job.node-label-expression="label1" -Dmapreduce.job.queuename="queue1"Spark 可以通在 spark-submit 添加参数来指定 label:
--conf spark.yarn.am.nodeLabelExpression=label1 \
--conf spark.yarn.executor.nodeLabelExpression=label14. 测试
执行 TPC-DS 项目来生成测试数据,在 hadoop 提交任务处指定 label,可以看到提交的 MR 作业都落在指定了 kunpeng 标签的单个节点上:

参考文档: